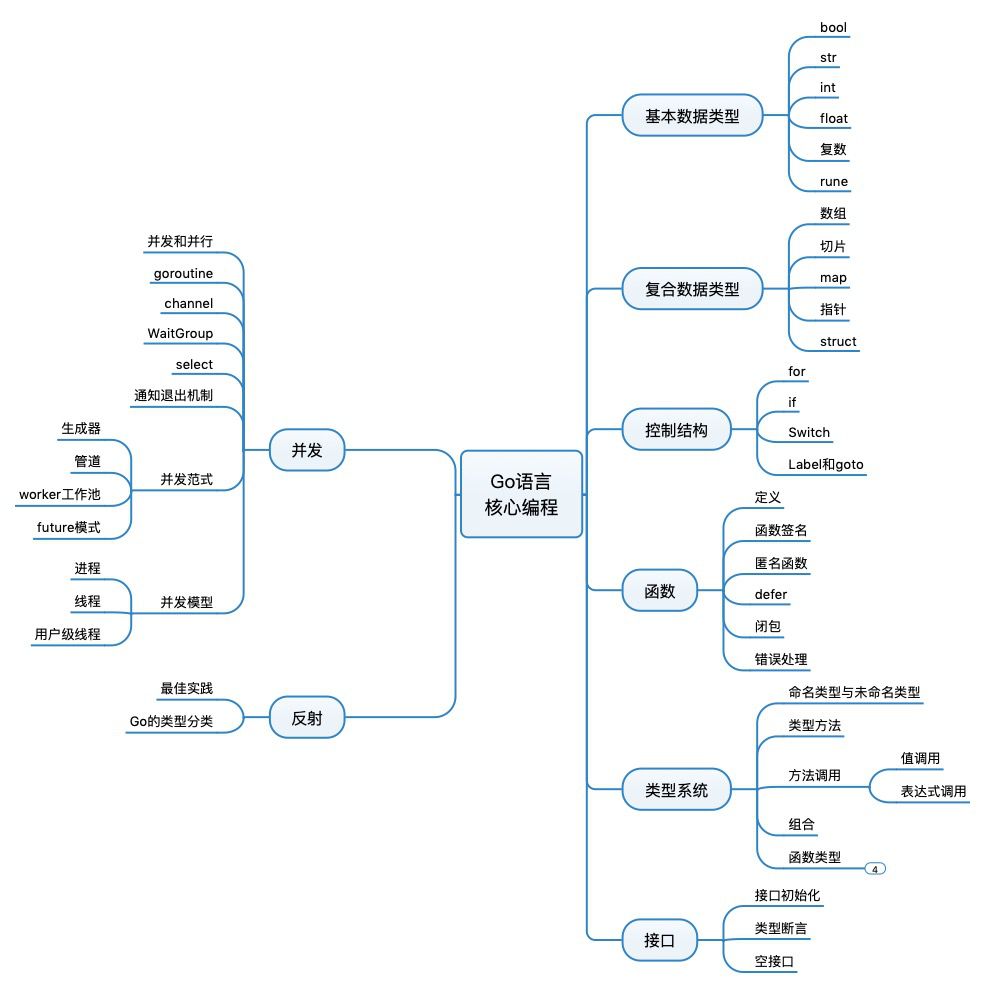
李文塔著
1. 基本数据类型
str
字符串是常量, 可以通过索引访问某个单元字节, 但不能修改。 底层是一个二元的数据结构, 一个是长度, 一个是指向字节数组的指针。
int
总共12种 byte、int、int8、int16、int32、 int64, uint、uint8、uint16、uint32、uint64、 uintptr 不同整形类型之间必须进行强制类型转换
rune
rune在GO内部是int32的别名(4个字节), byte是uint8的别名(一个字节)。 两者都是字符类型, 赋值时用单引号
float
包括float32和float64, 两个浮点数之间不应该用==或者!=进行比较, 应该用math库。
bool
var ok bool // ok is false(默认值)
复数
两种:complex64, complex128 var a complex64 = 3.1 + 6i var b = complex(2.1, 3) a := real(b) c := image(b)
2. 复合数据类型
指针
*T 出现在=的左边标识指针声明, 出现在=右边表示取指针的值 Go 不支持指针的运算
1
2
3
4
var a = 11
p := &a // *p 和 a 的值都是11
p ++ // error, 不允许
数组
数组创建完长度就固定了, 不可以再追加元素 数组是值类型的, 数组赋值或作为函数参数都是值拷贝 长度也是数组类型的组成部分, [10]int 和 [20]int 表示不同的类型
1
2
3
4
a := [...]int{1, 2, 3}
var b [2]int
for i, v := range a {
}
切片
数据结构中有指向数组的指针, 所以是一种引用类型 切片三元素: 底层数组的指针、元素数量、底层数组的容量
1
2
3
4
5
6
7
8
9
10
11
12
13
var array = [...]int{1, 2, 3, 4, 5, 6}
s1 := array[0:4]
s2 := array[2:]
a := make([]int, 10, 15)
d := make([]int, 2, 2)
copy(d, a) // copy只会复制d和a中长度最小的
a = append(a, 1)
str := "hello, 世界"
a := []byte(str)
b := []rune(str)
fmt.Println(a)
fmt.Println(b)
map
map也是引用类型, 可以使用range 迭代map,但不保证顺序。 go内置的map不是并发安全的, 并发安全的map可以使用标准包sync中的map 不要直接修改map value内的某个元素的值, 需要将value整体替换
1
2
3
4
5
6
7
8
9
mp := map[string]int{"a": 1, "b":2}
mp2 := make(map[int]string)
mp2[1] = "tom"
mp2[2] = "jerry"
delete(mp, 2)
for k, v := range(mp){
fmt.Println("key=", k, "value=", v)
}
struct
struc的存储空间是连续的, 其字段按照声明时的顺序存放。
1
2
3
4
5
6
7
8
9
type Person struct {
Name string
Age int
}
type Student struct {
*Person,
Number int
}
channel
interface
3. 控制结构
if
if 后面可以带一个简单的初始化语句, 并以分号分割, 该简单语句声明的变量的作用域是整个if语句块, 包括后面的else if 和 else 分支。
1
2
3
4
5
6
7
if x := f(); x < y {
return x
} else if x > z {
return z
} else {
return y
}
for
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
for init; condition; post { }
for condition {} // 等价于while 语句
for {} // while true
//访问map, 设计不好, 到底是返回一个参数, 还是两个?
for k, v := range map {}
for k := range map {}
//访问数组、切片
for index, value := range array{}
for index := rnage array{}
for _, value := range array{}
// 访问通道
for value := range channel{}
switch
通过fallthough语句来强制执行下一个case子句(不必判断条件是否满足)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
switch i := "y"; i { // 后面跟一个简单的初始化语句
case "y", "Y":
fmt.Println("yes")
fallthrough
case "n", "N":
fmt.Println("no")
}
var score int
var grade string
switch { // 替换 else if
case score >= 90:
grade = "a"
case score >= 80:
grade = "b"
default:
grade = "F"
}
goto & label
goto 语句只能在函数内跳转, 而且不能跳过内部变量声明语句。 goto 语句只能跳转到同级作用域或者上层作用域内, 不能跳转到内部作用域 continue、break可以配合label使用, 但label和continue、break在一个函数内。
4. 函数
定义 & 函数签名
首字母的大小决定了该函数在其他包的可见性。 函数的参数和返回值都需要使用()来包裹, 如果只有一个返回值, 而且非命名, 返回参数的()可以省略。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
fun funcName(param-list) (result-list) {
funcition-body
}
func A() { // 没有参数, 没有返回值, 默认返回0
}
func add(a, b int) int { // a int, b int的简写
return a + b
}
func add(a, b int) (sum int) {
sum = a + b //
retunr // 如果是sum := a+b, 这里要改成return sum, 覆盖返回变量sum
}
如果返回多个结果, 错误类型一般放最后一个 Go函数实参到形参的传递永远是值拷贝
不定参数类型必须相同, 而且必须是函数最后一个参数, 参数名相当于切片
1
2
3
4
5
6
7
8
9
10
func sum(arr ...int) (sum int) {
for _, v := range arr {
sum += v
}
return
}
slice := []int{1, 2, 3, 4}
array := [...]int{1, 2, 3, 4}
sum(slice...) //数组不可以作为实参传递给不定参数, 必须是slice
一个函数的类型就是函数定义首行去掉函数名、参数名
1
2
3
4
5
6
7
fmt.Printf("%T/n", add) // func(int, int) int
type Op func(int, int) int // 定义一个函数类型
func do(f Op, a, b int) int {
return f(a, b)
}
a := do(add, 1, 2) // 函数名add可以当作相同函数类型传参, 不需要强制类型转换
匿名函数
1
2
3
var sum = func(a, b int) int {
return a + b
} // 匿名函数直接复制给函数变量
defer
defer 后面必须是函数或方法的调用, 不能是语句 defer的实参在注册时通过值拷贝传递进去 主动调用os.Exit(int)退出进程时, defer将不再被执行 defer相对于普通的函数调用需要间接的数据结构的支持, 相对于普通函数有一定的性能损耗
闭包
闭包 = 函数 + 引用环境 闭包对闭包外的环境引入是直接引用, 编译器检测到闭包,会将闭包引用的外部变量分配到堆上。 对象是附有行为的数据, 而闭包是附有数据的行为 同一个函数返回的多个闭包共享该函数的局部变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
func fa(a int) func(i int) int {
return func(i int) int {
println(&a, a)
a += i
return a
}
}
f := fa(1)
g := fa(1) // g引用的闭包环境中的a和f的a不是同一个
println(f(1)) // 2
println(f(1)) // 3
println(g(1)) // 2
println(g(1)) // 3
错误处理
panic用来主动抛出错误, recover用来补获panic抛出的错误 recover() 只有在defer后面的函数体内被直接调用才能补获panic终止异常, 否则返回nil
1
2
3
4
5
6
7
8
9
10
11
12
13
14
defer recover()
defer fmt.Println(recover()) // 补获失败
func except(){
println("defer inner")
if err := recover(); err != nil {
fmt.Println(err)
}
}
func test() {
defer except() // 补获成功
panic("test panic")
}
函数并不能补获内部新启动的goroutine所抛出的panic Go提供了两种错误处理的方式, 一种是借助panic和recover的抛出补获机制, 另一种是使用error错误类型。使用规则为: a 程序发生错误导致程序不能容错继续进行, 此时应该调用panic。 b 程序虽然发生错误,但是程序能够容错继续进行, 此时应该返回error
1
2
3
4
5
6
7
8
9
10
11
// error 定义
type error interface {
Error() string
}
func Sqrt(f float64) (float64, error) {
if f < 0 {
return 0, errors.New("math: square root of negative number")
}
// 实现
}
5. 类型系统
命名类型与非命名类型
命名类型包括20个预声明的简单类型与用户自定义类型(type ) 未命名类型又称为类型字面量, Go中的复核类型都是类型字面量: array、slice、map、channel、pointer、function、struct、interface
底层类型
预声明类型和字面量类型的底层类型都是他们本身 自定义类型的底层类型是逐层递归向下查找的
类型方法
1
2
3
4
5
6
7
8
9
// 类型方法接收者是值类型
fun (t TypeName) MethodName (ParamList) (ReturnList) {
// body
}
// 类型方法接收者是指针类型
fun (t *TypeName) MethodName (ParamList) (ReturnList) {
// body
}
非命名类型不能自定义方法 方法的定义必须和类型的定义在同一个包中 新类型不能调用原有类型的方法, 但是底层类型支持的运算可以被新类型继承
值调用和表达式调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
type T struct {
a int
}
func (t T) Get() int {
return t.a
}
func (t *T) Set (i int) {
t.a = i
}
var t = &T{}
t.Set(2) // 方法值调用
t.Get() // 方法值调用
(T).Get() // 表达式调用
使用值调用方式调用时, 编译器会进行自动转换。 使用表达式调用时, 编译器不会进行转换。 T 类型的方法集是S *T类型的方法集是 S 和 *S
组合
在简写模式下, Go编译器优先从外向内逐层查找方法, 同名方法中外层的方法能够覆盖内层的方法。
- 若类型S包含匿名字段T, 则S的方法集包含T的方法集
- 若类型S包含匿名字段T,则S的方法集包含T和T的方法集
- 不管类型S中嵌入的匿名字段是T还是*T, *S的方法集总是包含 T 和 *T的方法集
函数类型
分为函数字面量类型和命名类型 type ADD func (int, int) int 字面量类型又包含有名和匿名, 有名即func add (int, int) int
6. 接口
一个具体类型实现接口不需要在语法上显示的声明,只要具体类型的方法集是接口方法集的超集, 就代表该类型实现了接口。
接口初始化
如果具体类型实例的方法是某个接口的方法集的超集, 则称该具体类型实现了接口, 可以将该具体类型的实例直接赋值给接口类型的变量。 接口被初始化后, 调用接口的方法就相当于调用接口绑定的具体类型的方法,这就是接口调用的语义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
package main
type Printer interface {
Print()
}
type S struct {}
func (s S) Print(){
println("Print")
}
var i Printer
// i.Print() 会报panic, 因为还没有初始化
i = S{}
i.Print()
接口方法调用不是一种直接调用, 有一定的运行时开销
接口的动态类型和静态类型
接口绑定的具体实例的类型称为接口的动态类型 静态类型本质就是接口的方法签名集合。 两个接口如果方法签名集合相同(顺序可以不同),则这两个接口在语义上完全等价, 它们之间不需要强制类型转换就可以相互赋值
接口断言
形式:
1
2
3
4
5
6
o := i.(TypeName)
// 一般用法如下
if o, ok := i.(TypeName); ok {
// body
}
- 如果TypeName是一个具体类型名, 则类型断言用于判断接口变量i绑定的实例类型是否就是TypeName。如果是的话, o的类型就是TypeName, 值是接口绑定的实例值的副本。 否则panic
- 如果TypeName是一个接口类型名,则类型断言用于判断接口变量i绑定的实例类型是否同时实现了TypeName接口。 如果是,则o的类型是接口类型TypeName, o底层绑定的具体实例是i绑定的实例的副本。
空接口
空接口 interface {}, 由于空接口的方法集为空, 所以任意类型都被认为实现了空接口,任意类型的实例都可以赋值或传递给空接口,包括非命名类型的实例。
7. 并发
并发和并行
- 并行意味着程序在任意时刻都是同时运行的 (时间点)
- 并发意味着程序在单位时间内是同时运行的 (时间段)
goroutine
- go 后面跟一个函数, 来启动goroutine
- go后面函数的返回值会被忽略
- 调度器不能保证多个goroutine的执行次序
- 没有父子goroutine的概念, 所有goroutine都是平等的被调度和执行的
- runtime.GOMAXPROCS(n) n 大于1表示设置GOMAXPROCS的值, 否则表示查询当前值
channel
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 创建无缓冲通道
c := make(chan datatype)
// 创建有缓冲的通道
c := make(chan datatype, 10)
// 写通道
c <- struct{}{}
// 读通道
<- c
// 关闭通道
close(c)
- 通道分为无缓冲的通道和有缓冲的通道。无缓冲的通道既可以用于通信, 也可以用于两个goroutine同步, 有缓冲的通道主要用于通信。
- goroutine 运行结束后, 写到缓冲通道中的数据不会消失
- 向已经关闭的通道写数据会导致panic
- 重复关闭通道会panic
- 读取已关闭的通道不阻塞不panic, 直接返回通道元素的零值。 可以使用comm, ok 语法判断通道是否已关闭
- 向未初始化的通道写数据或读数据都会导致当前goroutine永久阻塞
- 向缓冲区已满的通道写入数据会导致goroutine阻塞
- 通道中没有数据, 读取该通道会导致goroutine阻塞
WaitGroup
```go package main import ( “sync” )
var wg sync.WaitGroup
wg.Add(1) wg.Done() // 和wg.Add(-1)等价 wg.Wait() // 等待goroutine结束
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
### select
如果监听的通道有多个可读或可写的状态, 则select随机选取一个来处理
```go
package main
func main() {
ch := make(chan int, 1)
go func(chan int) {
for {
select {
case ch <- 0:
case ch <- 1:
}
}
}(ch)
for i := 0; i< 10; i++ {
println(<-ch)
}
}
通知退出机制
读取已经关闭的通道不会阻塞, 也不会panic, 而是立即返回该通道存储类型的零值。
并发范式
- 生成器
- 管道
- 固定worker池
- future
并发模型
- CSP最基本的思想是:将并发系统抽象为Channel 和 Process 两部分,Channel用来传递消息, Process用于执行, Channel和Process之间相互独立, 没有从属关系, 消息的发送和接受有严格的时序限制
- Go语言主要借鉴了Channel和Process的概念, 在Go中Channel就是通道, Process就是goroutine
- 多进程下, 每个进程都有自己独立的内存空间, 隔离性好、健壮性搞。进程间的通信需要多次在内核区和用户区之间复制数据
- 多线程是指启动多个内核线程进行处理, 线程的有点是通过共享内存进行通信更快捷, 切换代价小;缺点是多个线程共享内存空间,极易导致数据访问混乱, 健壮性不高
- 协程是一种用户态的轻量级线程, 协程的调度完全由用户态程序控制。
- 协程控制了线程数, 保证每个线程的运行时间片充足(减少切换次数)
- Go的并发执行模型就是一种变种的协程模型
8. 反射
反射是指计算机程序在运行时可以访问、检测和修改本身状态或行为的一种能力
Go的类型分类
最佳实践
- 在库或框架内部使用反射, 而不是把反射接口暴露给调用者, 复杂性留在内部, 简单性放在接口
- 框架代码才考虑使用反射, 一般业务代码没有必要抽象到反射的层次
- 除非没有其它办法, 否则不要使用反射技术。