爬虫概论
本文只是简单记录下前段时间一个爬虫项目使用到的知识点, 并不涉及太多具体的代码实现。 像验证码破解、scrapy框架解析以后可能会用单独一篇文章来详细讲解。
1. 简单的爬虫脚本
Python 的 requests库
import requests
url = "http://www.baidu.com"
resp = requests.get(url)
print(resp.content)
特点: 简单、易用, 功能强大,pythonic。 可以添加header、代理、认证信息等, 满足大部分时候的需求。 例子: you-get源代码里很多涉及到网络请求的地方用的都是requests, 公司的项目中很多涉及到网络请求的地方也都是用的requests。
2. 如何提升网络请求效率
我们知道, 网络请求是很慢的, 远慢于代码执行时间和本地磁盘的I/O时间。那么如果想要爬取大量的网页数据, 要怎么做呢?
- 阻塞请求, 上个请求的结果返回后再发起下一个请求——太慢!
- 多进程,同时开启多个进程来发起网络请求——浪费资源、同步麻烦
- 多线程,利用Python GIL的特性, 但个线程执行I/O操作时, 在响应返回前可以让出GIL。
- 协程——轻量级线程, 更加高效。给每次使用的socket(设置成非阻塞)注册回调函数➕底层调用非阻塞型的I/O操作(selector)。具体可以参见我讲协程的那篇文章。
3. 爬虫框架——scrapy
为什么有了requests还需要像Scrapy这样的爬虫框架?
- 大规模爬取
- 模块化处理复杂的爬取流程
- 高效率的网络请求,其使用的Twisted运用协程来提高网络请求效率
- 高可扩展
Scrapy 内部的各个组件和执行逻辑如下图所示,其中几个组件的作用如下:
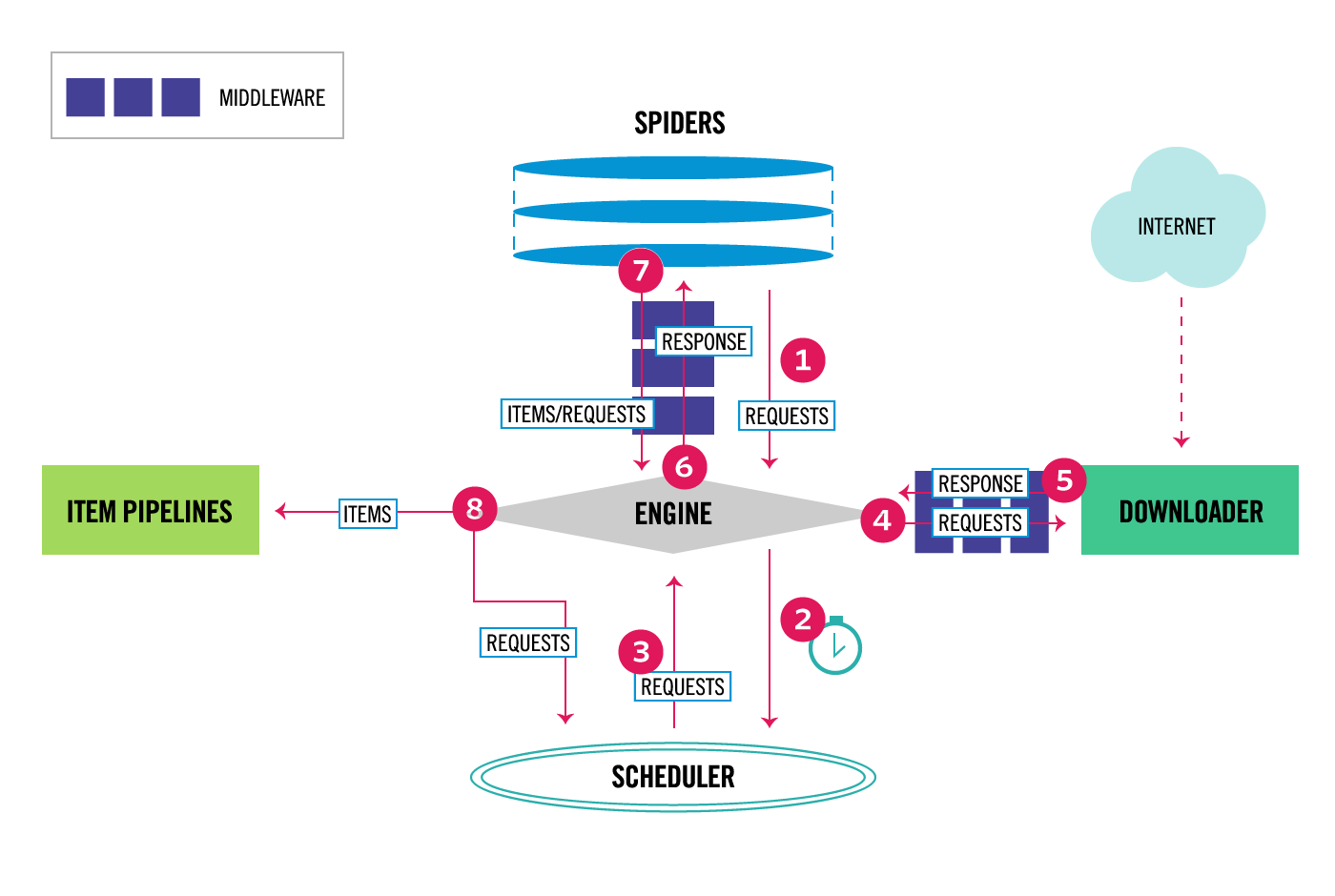
- Spider: 我们写爬虫的入口, 可以指定爬取的url以及对爬取结果的处理函数——Parser, 发出请求——Request对象
- Scheduler: 调度器, 用来按优先级调度爬虫队列中各个requests
- Downloader: 下载器, 用来发出网络请求, 并取得请求结果——Response 对象
- ITEM PIPELINES: 处理器, 对返回结果——Response对象做一系列的处理, 例如清洗、过滤、格式化、存储等
- Middleware: 中间件, 包括spider中间件和downloader中间件, 可以对requests和response对象在做些额外的处理,例如添加代理、指定UserAgent、保存cookie等
受限于篇幅, 本文就先不展开讲了, 以后有机会的话可以单独写一篇文章分析Scrapy的源码。
4. 扩展scrapy框架——分布式
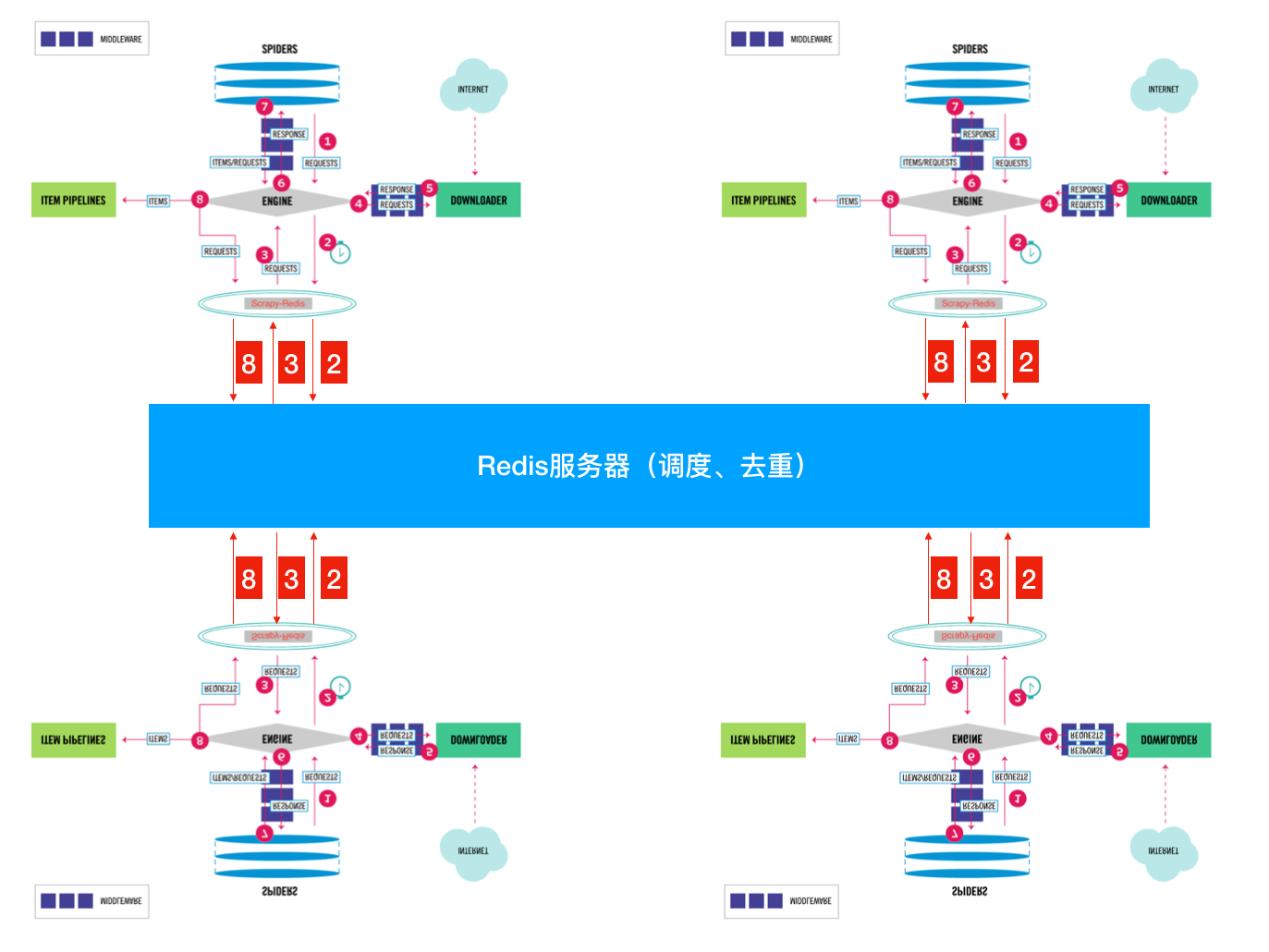
单个机器的性能总是有限的,scrapy默认储存请求队列是存储在本地的内存里,这样可以快速开发, 但不适合扩展和数据持久化, 实际上, 我们只需要改造下SCHEDULER模块, 把存储请求的部分改用redis, 就可以实现分布式爬虫框架。
from scrapy.scheduler import Scheduler
class CustomScheduler(Scheduler):
def enqueue_request(self, request):
# url bloom去重
# 把requests对象存入队列(用redis实现)
self.queue.push(request)
def next_request(self):
# 从队列中取出一个requests对象
self.queue.pop(request)
def has_pending_requests(self):
# 爬虫程序在空闲时会一直调用这个方法来查看是否有待爬序列
return self.len(self.queue)
其实, 如果不对每次请求入队列和出队列之前
做其它操作(如自定义去重)的话, 只需要把scheduler使用的queue改用自定义的使用redis存储的队列就可以了,此外, 自定义队列时, 还可以对出队列的优先级做自定义的调整,比如定时出队列、特定的优先级等等, 使用redis做队列的存储之后, 多个机器同时爬取的流程如下图所示, 其实就是多个机器共用一个Scheduler模块。
5. 中间件
利用中间件, 我们可以在每次请求前给requests对象添加cookie(比如添加登录后的cookie来保持登录状态)、指定header、设置代理等, 来做一些应付反爬虫机制的工作。
class CustomUserAgentMiddleware:
def process_request(self, request, spider):
agent = random.choice(agents)
request.headers["User-Agent"] = agent
如上所示,自定义中间件非常简单, 只需要对传进来的requests对象做一些操作即可, 当然, 在settings文件里要指定使用自定义的中间件, 并指定一个合适的优先级(优先级决定了多个中间件的执行顺序)
6. 登录
有些网站的特定内容时需要登录后才能获取的, 对于登录, 简单的网站, 用Post 请求传送用户+密码即可获得登录后的cookie, 但对于一些登录参数复杂的网站,比如知乎(改版后)、微博等, 则需要能真正模拟用户登录行为的工具——Selenium
Selenium 内置了多款浏览器, 支持Chrome、Firefox、PhantomJS等, 我推荐使用最新Chrome 的headless模式, 对JS的渲染更加完全, 而Selenium最新版也已经放弃了对PhantomJS无头浏览器的支持。 我们用selenium+Chrome(headless mode)来模拟用户的点击和输入操作, 从而调过了对复杂登录参数的解析,登录后把cookie保存下来, 这样scrapy发起请求时带上保存的cookie就可以访问需要登录授权的网页内容了。
7. 验证码
爬虫时碰到验证码是很头疼的, 虽然有些第三方库可以根据验证码图片识别出其中的数字, 但对于稍微不那么规则的验证码识别效果就很不理想了。用机器学习可以有效的破解特定的验证码, 但需要大量的数据和人力标注,而且针对性强,验证码稍微有点变化就不适用了。鉴于此, 我采用直接调用第三方打码平台(推荐超级鹰)来识别, 单词识别的费用只有几分钱, 登录的次数毕竟很有限, 相比于自己投入大量时间来研究破解方案,还是很划算的。所以, 对于验证码这块, 我的破解思路如下:
- 用Selenium + Chrome(headless)打开登录网站, 输入用户、密码
- 找到验证码元素, 用Selenium截图,保存Image对象
- 调用第三方接口, 识别验证码
- 把第三方返回的验证码输入验证码对应的地方, 点击登录
- 获取跳转后的网页元素, 验证是否成功登录
- 保存登录后的cookie
- 下次访问时带上保存的cookie即可(要检查cookie是否失效)
其中, 验证码图片的获取又可以分为三种情况:
- 是base64格式的图片——直接转化成图片就行
- 是url, 但每次请求返回的是相同的图片——调用requests下载
- 是url, 且每次请求返回的图片不一样——找到验证码图片元素,截图保存
当然, 还有一种是滑动验证码, 这种,用selenium也是可以来模拟人的拖拽的,只要控制好滑动的速度不要太平缓或有规律就行了。
8. 动态渲染
有时候用浏览器打开看有很多内容的网页, 用爬虫爬到的确实近乎空白的, 这是因为现在很多网页出于性能的需要,一些元素是异步加载的。 对于这些需要动态渲染的网页, 如果能轻松的拿到它请求的api肯定再好不过了, 但对于一些不太容易发现api或者api请求不好伪造的情况(比如很多多不知道什么规则生成的参数), 我们可以用一些插件来实现网页的动态渲染。 用selenium肯定可以动态的来渲染页面, 毕竟使用的是一个真实的浏览器, 但这样代价太高,对于大规模的爬取肯定是要不得的。对于我们的scrapy爬虫框架, 使用splash插件就再合适不过了, 把splash插件集成到scrapy的Downloder的中间件里, 这样程序里发送的网页请求实际送到了splash服务, 而返回的response对象则是已经渲染好的页面。 所以, 对于需要动态渲染的页面, 有以下三中方法:
- 捕获和伪造请求API
- 用Seleinum + chrome
- scrapy + splash
9. 一些建议
- 能不登录就不登录——简单、防止封号。
- 使用深度优先, 早早的将爬取结果落到本地。
- 速度主要限制在网络请求上, 没有必要太多的进程,使用协程就可以实现很高效的爬取。
- 对于大量爬取的网站, 最好维护一个高可用的代理池和多个可用账号, 防止封IP、封账号。