未经审视的人生是不值得一过的。 ——苏格拉底
想法
很多时候我在想, 为什么生活中一些重要的事情例如读书、锻炼、学习难以持之以恒呢?为什么不能像爬山那样向着一个目标不断前行、越挫越勇呢?我觉得很大一个原因是这些东西都不太好量化, 很难有实时的正反馈激励。而这篇博客所想要的则是尽可能的对自己的生活实现量化, 这样更便于自省和规划。目前博客后台已经有了plan规划和消费记录功能, 现在想做的是对自己的上网记录做一个统计, 就像机器学习那样, 只有不断的输入干净优良的数据才能训练出一个好的系统, 如果自己每天浏览的都是一些乱七八糟的网站那有什么理由相信自己不是彻彻底底的庸人一个呢?
- 偶尔打开chrome的浏览记录惊讶于自己竟然在一小时内打开了这么多网页
- 能不能把自己的浏览记录存到mysql里实时查看和分析呢?
- 爬虫 + 简单的图表分析
调研
- 抓包
历史记录 、 history
https://myactivity.google.com/myactivity?utm_source=chrome_h
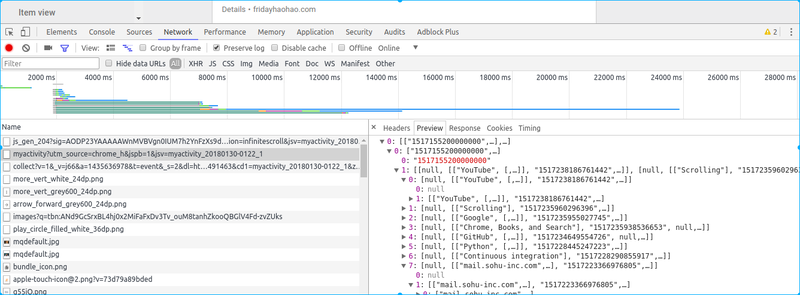
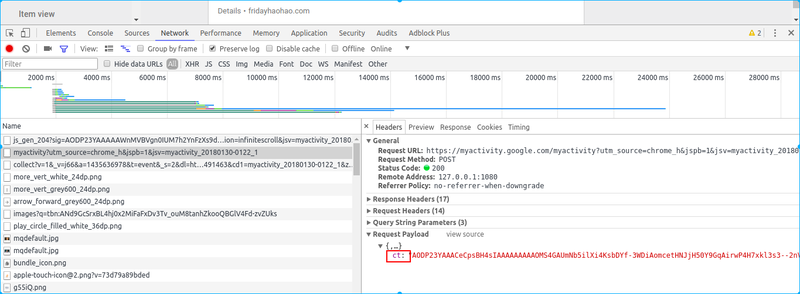 猜不透, 估计是一堆cookie加上一堆JS中的某一个算出来的签名
猜不透, 估计是一堆cookie加上一堆JS中的某一个算出来的签名 - 全球最大男性同性交友平台——GitHub
有没有现成的呢? 一个插件—— history master
almost there, 但数据统计有用信息太少 - Google API —— chrome 插件 chrome的浏览记录存储在本地sqlite数据库里 , 好像可以直接拿来用
初步实现
- linux下sqlite 路径: .config/chromium/Default/History
Look Inside
1 2 3 4 5 6 7 8 9 10 11 12 13
$ sqlite3 History SQLite version 3.11.0 2016-02-15 17:29:24 Enter ".help" for usage hints. $ sqlite> .table downloads meta urls downloads_slices segment_usage visit_source downloads_url_chains segments visits keyword_search_terms typed_url_sync_metadata $ sqlite> .header on $ sqlite> select * from urls limit 2; id|url|title|visit_count|typed_count|last_visit_time|hidden 53|http://www.zhihu.com/#signin|(1 封私信 / 11 条消息)首页 - 知乎|19|0|13160970803817358|0 57|https://www.youtube.com/|YouTube|92|0|13161102351592757|0
有用信息: url 、 title、 visit_count 、last_visit_time (时间戳形式)
- 每天定时上传sqlite到服务器 scp History.sql to remote Server
1
*/10 9,10 * * * scp /home/friday/.config/chromium/Default/History root@secreate:/root/myblog/files
- 定时分析sqlite 获取浏览数据 ```python import sqlite3
history_db = ‘/root/myblog/files/History’ con = sqlite3.connect(history_db) cu = con.cursor()
def get_latest_100_record(offset=0): sql = “"”select datetime(last_visit_time/1000000-11644473600, “unixepoch”) as last_visited, url, title From urls order by last_visited desc limit 100 offset %s””” % offset cu.execute(sql) results = cu.fetchall() return result
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
存入数据库
* url 、 visit_time、title、 domain、domain_type
* 根据url获取domain——正则表达式
`domain = re.findall('http[s]{0,1}://(.*?)[/?]{1}', url + '/')[0]`
问题:
* 时间比较难以掌握
* 强依赖本地电脑
* 多客户端同步不及时、不完全
## 另一种实现——Selenium
虽然想用python调用接口来获取数据比较困难, 但对Selenium来说这都不是问题。
1. 模仿登录google账户
```python
from selenium import webdriver
chromedriver_path = '/root/myblog/chromedriver'
browser = webdriver.Chrome(executable_path=chromedriver_path)
open_google_auth(browser)
def open_google_auth(browser):
url = 'https://accounts.google.com/signin/v2/identifier?hl=zh-CN&passive=true&continue=https%3A%2F%2Fmyactivity.google.com%2Fitem%3Futm_source%3Dchrome_h&flowName=GlifWebSignIn&flowEntry=ServiceLogin'
browser.get(url)
time.sleep(10)
# 找到登录框
browser.find_element_by_xpath('//*[@id="identifierId"]').send_keys('YourAccount') # 输入Google账户
browser.find_element_by_xpath('//*[@id="identifierNext"]/content/span').click()
time.sleep(10)
browser.find_element_by_xpath('//*[@id="password"]/div[1]/div/div[1]/input').send_keys('YourPassword')
browser.find_element_by_xpath('//*[@id="passwordNext"]/content/span').click()
print('auth success')
-
打开history记录网页 上一步登录成功后会自动跳转到history记录页(continue的值)
-
获取浏览信息, 保存到mysql ```python elements = browser.find_elements_by_css_selector(‘div.fp-display-block-text-holder.layout-align-space-between-stretch.layout-column.flex’)
def analysis_elements(elements): for element in elements: content = element.find_element_by_css_selector(‘h4.fp-display-block-title.t08’).get_attribute(‘innerHTML’) timer = element.find_element_by_css_selector( ‘div.fp-display-block-details.t12.g6.layout-align-start-center.layout-row’).get_attribute(‘innerHTML’)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
content 和 timer获取到的html源码如下:
```python
content_html = """ Visited
<!----><a ng-if="::!!item.getTitle().getUrl()" ng-href="https://myactivity.google.com/item?utm_source=chrome_h" ng-click="::ctrl.playVideo(item.getTitle().getUrl())" target="_blank" href="https://myactivity.google.com/item?utm_source=chrome_h">
Google - My Activity
</a><!---->
<!---->
"""
timer_html = """<!----><span ng-if="::!summaryItem">1:33 PM</span><!---->
<!----><span ng-if="::!summaryItem">•</span><!---->
<span class="fp-display-block-details-string">
Details
</span>
"""
使用简单的正则表达式就可以获取到本条浏览记录的url、title和visit time visit time 有个比较头疼的问题, 浏览记录是按天分组的, 所以visit timer只显示当天的时间, 如上午10:00, 下午2:00 等 解决办法, 每天只获取当天的浏览数据(最晚一次获取时间是23:55), 如何和昨天的数据分开? ——根据展示日期元素的位置
1
2
3
4
5
6
7
8
9
10
11
h2 = browser.find_elements_by_css_selector('h2.t08.fp-date-block-date') # 展示日期的元素
yesterday_height = h2[1].location['y']
...
def analysis_elements(elements, yesterday_height):
for element in elements:
if element.location['y'] >= yesterday_height:
print('early than yesterday, break')
break
...
- One more thing —— xvfb
服务器上是不能显示图形界面的, 即使安装了chrome浏览器也打不开。 需要借助xvfb来捕获显示。
Xvfb 可以直接处理 Window 的图形化功能,並且不會把图像输出到屏幕上,也就是说,就算你的电脑沒有启动 Xwindow , 你仍然可以执行图形程序。
1 2 3
sudo apt-get install xvfb export DISPLAY=:10 xvfb-run python capture.py
问题与改进
- 每天都登录好几次太过频繁, 会不会被google察觉? —— Set Cookie and load Cookie
```Python
set cookie
cookies = browser.get_cookies() pickle.dump(cookies, open(“cookies_firefox.pkl”, “wb”))
load cookie
cookies = pickle.load(open(“cookies_firefox.pkl”, “rb”)) browser.get(‘http://myactivity.google.com’) # 打开该网站之后才能set cookie for cookie in cookies: # cookie[‘domain’] = ‘myactivity.google.com’ firefox 需要, chrome不需要 browser.add_cookie(cookie)
1
2
3
4
5
6
7
8
9
10
11
12
2. 默认只展示最新100条浏览记录
* 每一小时执行一次脚本 ——太累
* scroll
3. scroll Problem
`browser.excute_js("window.scroll(0, y)")` Not Working —— 页面Overflow
解决办法——sendKeys PageDown
```python
page = browser.find_element_by_id('main-content') # 主页面
for i in range(1, 101):
page.send_keys(Keys.PAGE_DOWN)
time.sleep(1)
Still Not Working, Element Not Focus ? 查询后发现是selenium使用chrome的一个历史遗留bug, github相关issue从2014年讨论到了2017年都没有修复。。。 于是, 只能换FireFox!
后来发现其实可以先选中可以滚动的页面然后再滚动:
1
2
3
4
5
6
7
8
scroll_try = 1
while len(h2) < 2 and scroll_try < 100:
time.sleep(1)
scroll_try += 1
browser.execute_script("""
var scroll_btn = document.getElementById("main-content");
scroll_btn.scroll(0, {});""".format(2000*scroll_try))
h2 = browser.find_elements_by_css_selector('h2.t08.fp-date-block-date')
浏览记录分析
目前我的博客采用了xadmin后台, 所以mysql中有了数据后可以很方便的转换成图表显示:
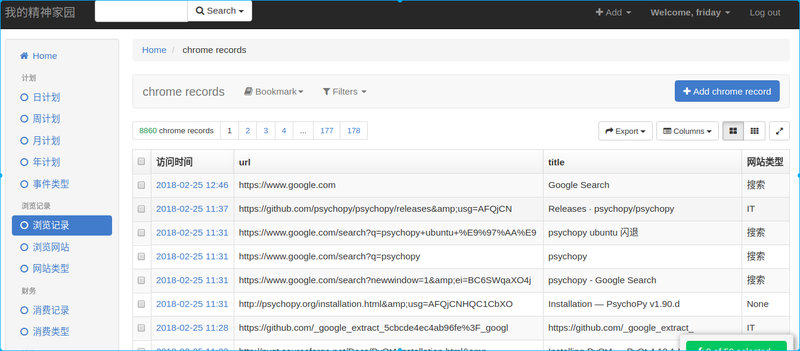 很方便的, 可以根据总浏览次数做个排序
很方便的, 可以根据总浏览次数做个排序
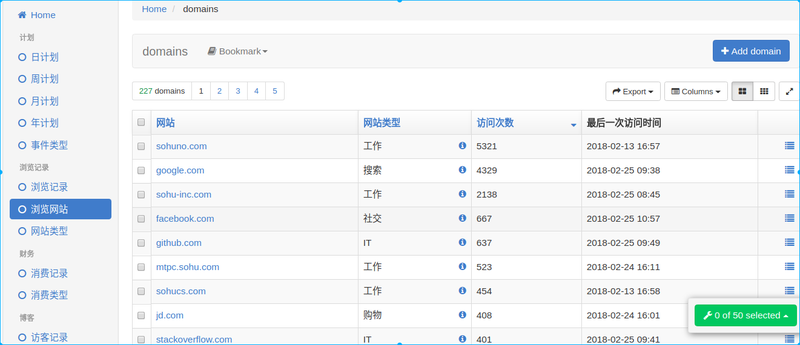
后续的话可以根据网站分类和浏览时间实现一些简单的统计分析。